Chrome Developer Tools 使用技巧
console.log()
占位符 %o 它接受对象,%s 接受字符串,%d 表示小数或整数,%c CSS 值的占位符,对应的后面的参数必须是 CSS 语句
如:
console.log('%s 的价格是 %d 磅 %d 便士', '衬衫', 9, 15) |
输出:衬衫的价格是 9 磅 15 便士
如:
console.log('I am a %cbutton', 'color: white; background-color: orange; padding: 2px 5px; border-radius: 2px') |
输出:I am a button
console.dir()
console.warn()
输出警告信息,字的颜色是黄色的,用于区分或过滤掉无用的输出
console.table()
将数据以表格的形式输出,对于数据列表的输出更容易观察其数据结构,并且点击输出的表头可以对数据排序
第二个可选参数是需要输出的字段。默认输出所有字段
console.table(data) // 输出全部 |
console.count()
计数器,可以用来统计代码被执行的次数
for (let i = 0; i < 5; i++) { |
输出结果为:
odds: 1 |
console.countReset() // 可以使用它重置计数器。 |
console.time()
是一个用于跟踪操作时间的专用函数,可以用来跟踪 js 的执行时间
const a = () => { |
选择 DOM 元素 $ 和 $$
- 在谷歌开发控制台中可以使用
$('选择器')类似于 jquery 的方式选择 DOM 元素
$(selector) 等效于 document.querySelector(selector)$$(selector) 等效于 document.querySelectorAll(selector)
inspect($('selector'))将检查与选择器匹配的元素,并转到 Elements 选项卡
$0,$1,$2等可以获取最近检查过的元素,即通过$0即可直接获取当前高亮的元素,$1可以获取上一个高亮的元素
将页面转换为可编辑状态
在 Console 中输入: document.body.contentEditable = true
之后页面中的内容即为可编辑状态,可以编辑 DOM 中的任何内容
查找与 DOM 中的元素关联的事件
getEventListeners($('selector')) 返回一个对象,其中包含绑定到该元素的所有事件
或 控制台 => Element => EventListeners
监控事件
监视绑定到 DOM 中特定元素的事件,然后在它们被触发后立即将它们记录在控制台中
// 监控绑定到 '#box' 元素的所有事件 |
检索最后一个结果的值
$_ 表示控制台中最近一次返回的值
'Hellow World'.split(' ') |
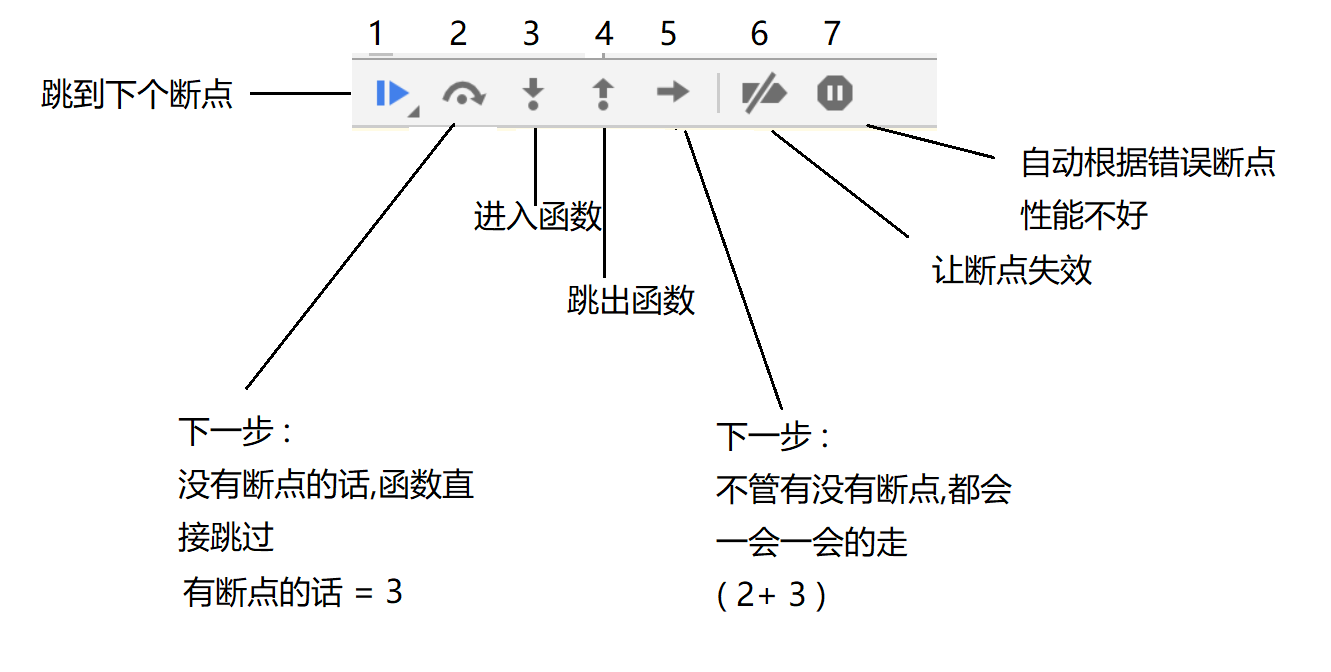
断点调试
- 跳到下个断点, 如果后面没有断点了,那么代码直接执行完
- 单步调试 : 下一步 没有断点的话,函数就直接跳过
- 单步调试 : 进入函数
- 单步调试 : 跳出函数
- 单步调试 : 下一步 不管有没有断点,都会一步一步的走,纯碎的下一步
- 让所有的断点失效
- 自动根据错误断点
一键重新发起请求
在与后端联调接口时比较方便,不用刷新页面,不用走页面交互
控制台 - Network - 选择要重新发送的请求 - 右键选择Replay XHR(只有xhr请求才有)
在控制台修改入参重新发起请求
同样方便与后端联调接口
控制台 - Network - 选择要重新发送的请求 - 右键 Copy - Copy as fetch - 控制台粘贴代码, 修改参数回车
复制js变量
鼠标放在一个变量上,右键 Copy Object/String…
或 在控制台中使用 copy() 函数,将对象作为入参执行即可
将节点或变量保存为全局变量
鼠标放在一个Element节点或变量上,右键 Store xxx as global variable,在Console中将可以使用该变量
网页截图
可以截取指定节点或全部网页内容
使用前先打开控制台
截取全部网页内容:ctrl/cmd + shift + p 执行Command命令,输入Capture full size screenshot 按下回车
截取部分网页内容:先在 Elements 中选中要截取的节点,ctrl + shift + p 执行Command命令,输入Capture node screenshot 回车
展开所有DOM元素
调试元素时,在层级比较深的情况下,你是不是也经常一个个展开去调试?有一种更加快捷的方式
Alt/Opt + click(需要展开的最外层元素)
实时表达式
点击Console面板中的 小眼睛,输入一个 js 表达式,回车,该表达式将会在Console面板里置顶,并动态刷新表达式的值



